R opens lots of doors to interesting stories in data. For this project, I decided to try to find them within American history. I tested the sentiment of presidential inaugural addresses throughout American history to see where it would lead me.
Inaugural Sentiment in American History
by Patrick Larsen
Note: arrow symbols are difficult to transport from RStudio into Brackets, so certain assignment operators (particularly ones that point left) have been replaced with a simple =.
My basic hypothesis for this specific test is if we see notable trends in inaugural addresses (such as irregular occurences of negative words about money), then we will be able to reasonably predict the presence of a historically significant event. If we are able to predict what that event might look like (such as being able to predict economic strife), then the test has been very successful. This is similar in some ways to my hypothesis from my last project - I will use it here to test something more specific, a sub-hypothesis.
I tested this using speeches gathered from gutenberg.com and CNN. They were very easy to copy into a UTF-8 TextEditor document and then use in RStudio. My basic process began with arranging the text by word, and then ordering and arranging the data by the number of times a specific word was used. This is the sample code for those steps, including the packages that you'll need, with "president" as our variable:
library(tidyverse)
library(ggplot2)
library(tidytext)
library(scales)
president = readLines("president.txt")
presidentDF = data.frame(text = president)
president_document_lines = unnest_tokens(presidentDF, input = text, output = line, token = "sentences", to_lower = F)
president_document_lines$lineNo = seq_along(president_document_lines$line)
presidentWords = president_document_lines %>% unnest_tokens(output = word, input = line, token = "words")
presidentWords2 = presidentWords %>% anti_join(stop_words, by = c("word" = "word"))
presidentWords3 = presidentWords2 %>% count(word, sort = TRUE)
presidentWords3 %>% top_n(10) %>% ggplot(aes(reorder(word, n), n)) + geom_bar(stat = "identity") + coord_flip()
In the case of the first ever U.S. presidential inaugural address, delivered by George Washington on April 30, 1789, we are left with this:
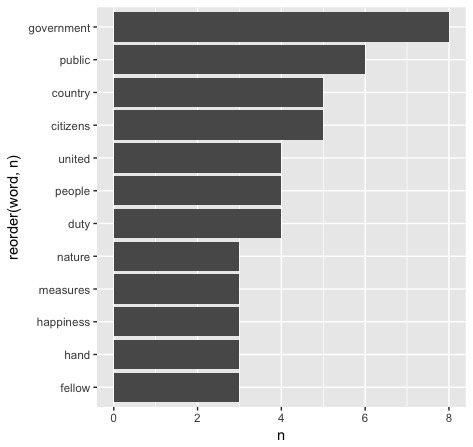
As of now, we are just looking at the most commonly used word in his speech.
Next, I dug more into the dataset, trying to arrange it in a way that was appopriate to our test. This includes removing words like "I'm" or "it's," and binding it with our sentiment database, "bing". Then plot!
presidentWords3 %>% filter(!word %in% c("i'm", "don't", "it's")) -> presidentWords4
president_bing_counts = presidentWords4 %>% inner_join(get_sentiments("bing")) %>% group_by(word) %>% count(n, sentiment, sort = TRUE) %>% ungroup()
president_bing_counts[order(president_bing_counts$n, decreasing=TRUE), ] -> president_bing_counts2
president_bing_counts2 %>%filter(sentiment=="negative") -> president_bing_negative
president_bing_negative %>% head(5) %>% mutate(word = reorder(word, n)) %>% ggplot(aes(word, n, fill = sentiment)) + geom_col(show.legend = FALSE) + facet_wrap(~sentiment, scales = "free_y") + coord_flip()
president_bing_counts2 %>%filter(sentiment=="positive") -> president_bing_positive
president_bing_positive %>% head(5) %>% mutate(word = reorder(word, n)) %>% ggplot(aes(word, n, fill = sentiment)) + geom_col(show.legend = FALSE, fill="#70ea89") + facet_wrap(~sentiment, scales = "free_y") + coord_flip()
What we end up with for Washington's first address are these two graphs:
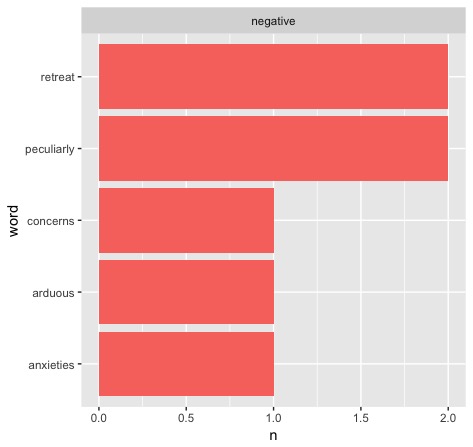
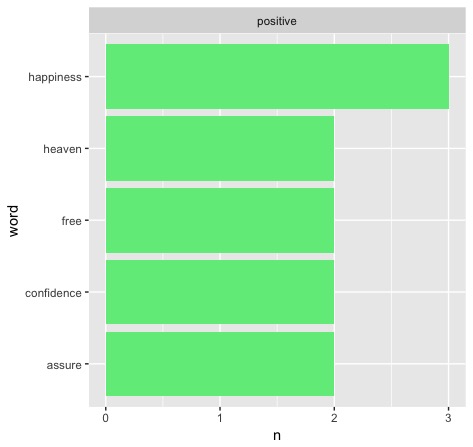
Ultimately, this is the first apparent problem we run into (given that our code is correct - which it fortunately is). As we can see, the first result we run into is sorely limited. The highest that any of these "most common" words reach is 3 - if all of the results look like this, it could be hard to tell when we have a significant event - or maybe it will provide us with lots of interesting outliers. Let's explore some of the possibilities.
Most simply, we could change our sentiment lexicon from "bing" to either "afinn" or "nrc." For our purposes, we'll only try "nrc" because of its similarity to "bing." The only thing we need to change is "bing" to "nrc" each time it appears, which is made very easy using RStudio's find/replace feature. Here's what we get when we test Washington's first address:
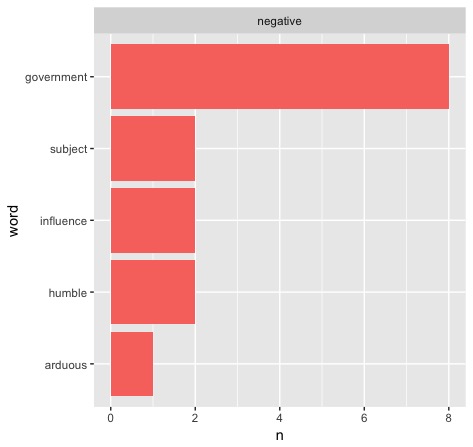
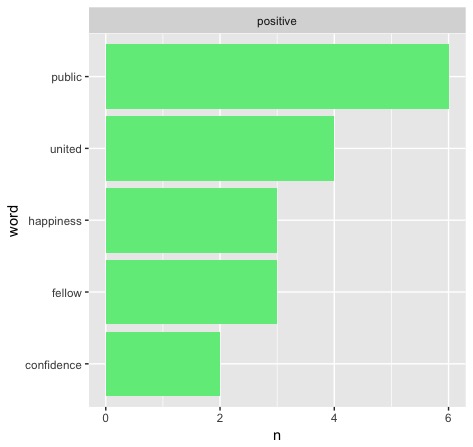
Well, that's not great. Our numbers may be better (something a few more tests seem to prove, but that's for a different report), but it's definitely not okay that "government" is a negative word. Most presidents will likely disagree with that sentiment, so it would not be appropriate to use a sentiment lexicon that is of this opinion. Back to Bing!
Another possibility for getting more out of our data is to look at larger subsets. To test this out, let's look at data from every presidential inaugural address in American history. We'll use the same base code with a .txt file of every speech, ensuring that we're back to using "bing." First, we find the most commonly used words:
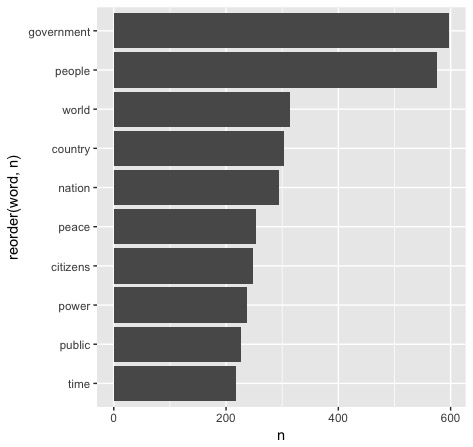
My suspicions of "nrc" have officially been confirmed. Using a lexicon that marks "government" as negative would have frankly ruined our data. The history of American presidential inaugurations would appear to be a very dreary one. Let's move on to our sentimental split:
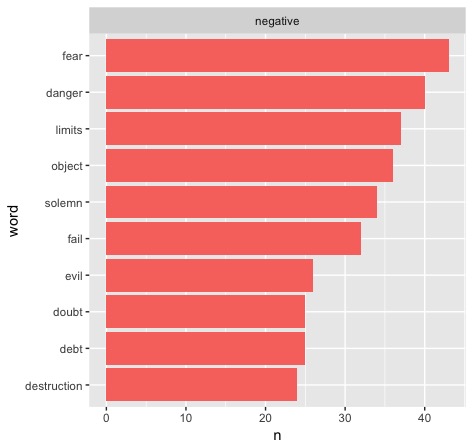
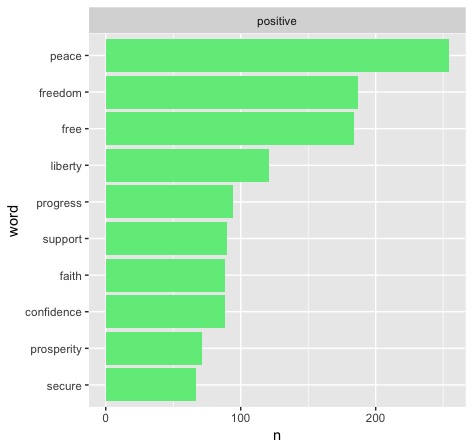
The most notable thing here is the gap between the most common positive words and the most common negative words, strictly in numbers. It's not hard to see that inaugural proceedings are in fact intended to be positive, which only makes good sense. A lot of the words seem to be empty or standby buzzwords that have been familiar throughout American political history - "peace," "fear," "freedom." Some are a little more specific, like "evil" (opposing military powers) or "debt" (money problems). We could certainly zoom in on these for a more specfic test, but there's another thing I'm interested in.
One of the top 10 positive words is "progress." This seems at first to be another one of the empty buzzwords that crops up time and time again, but I'm interested in the political implications that it holds. At this point in American history, "progressive" is certainly tied to left-leaning ideologies - is this at all reflected in inaugural addresses? Is it a more recent thing?
This leads me to my specific sub-hypothesis: if we see a rise in the occurences of the word "progress" in recent years (1920s and on), then we will see a noticeable split in the parties of the presidents that use it, specifically skewing towards Democrats.
We'll use the same code as before, and run through each president.
Only seven total of the inaugurations featured enough uses of the word for it to reach the top five positive words in the given speech. Four of these seven speeches and 34 of the 46 total uses of the word in these speeches fall after 1900. So we see that it is most commonly used more recently, but do the party lines reflect my hypothesis? To answer that, here are the four speeches in question:
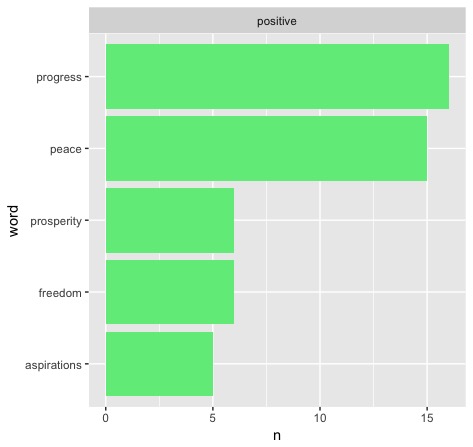
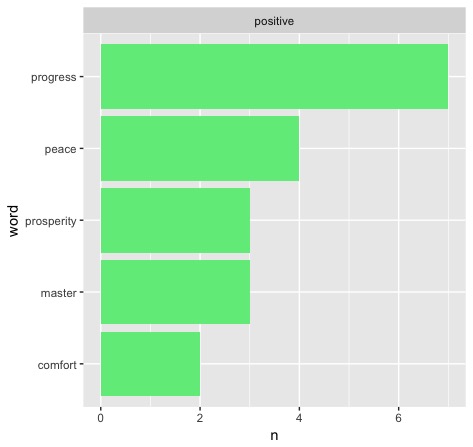
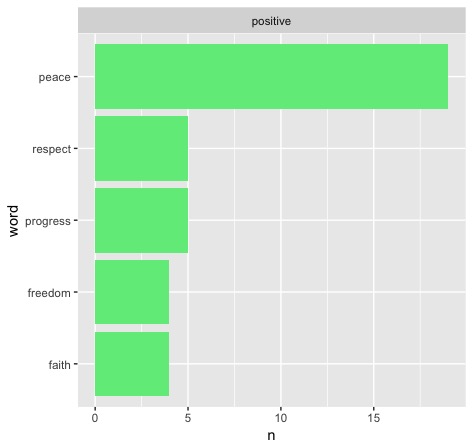
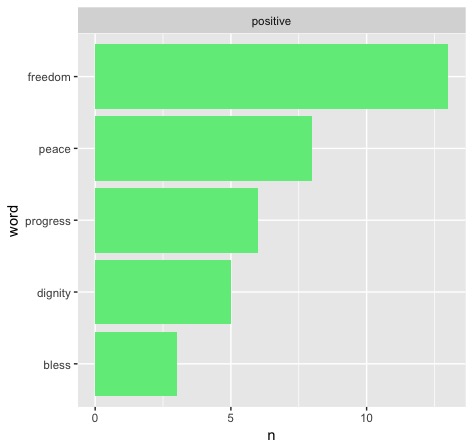
In order, that is Hoover 1929, FDR 1937 (second term), Nixon 1973 (second term), and Reagan 1985 (second term). Clearly, my hypothesis is disproven - the results do not skew towards Democrats, but Republicans. Hoover alone makes up for 16 uses, something that begs further reading - what does history say to inform this decision? As it turns out, Hoover wanted to be FDR before FDR even had a chance to - but his domestic programs were overshadowed by none other than the Great Depression. This contributed heavily to his defeat in the next election and maybe has something to do with FDR laying off the "progress" message until his second address.
Reflection:
Although my specific experiment was unsuccessful, my overall goal to find interesting, surprising stories was successful. Truth be told, this dataset would be more suited to someone with a stronger working understanding of American political history - but perhaps that's the beauty of this type of work. Because I have documented the basic process of this work, someone else can piggyback off of it and find something very cool - just like all the work we've been doing in our class.